금까지 살펴봤던 Density Estimation은 Data에 Label이 존재하지 않는 Unsupervised Learning에 해당한다. 이는 머신러닝의 일부에 해당한다. 그렇다면 다른 Learning의 방법은 어떤 것이 있는지 살펴보자.

Unsupervised Learning은 주어진 데이터의 Target Output 이 존재하지 않았다. Ground Truth 값이 없다고도 표현한다. 즉, Objective는 데이터의 Interesting Pattern을 찾는 것이다. 이 중에 두 가지의 대표적인 케이스가 존재하는데 첫째는 Density Estimation이고 둘째는 Clustering이다. Density Estimation은 샘플 데이터의 분포를 모델링하는 것이고 Clustering은 비슷한 샘플 데이터끼리 그룹핑하는 것이다.

Density Estimation을 다시 정리하자면 추출된 데이터로부터 확률적 모델을 만드는 것이다.

Clustering이란 비슷한 데이터 샘플끼리 묶는 것을 의미한다.

보통 Dataset은 행렬로 저장된 xml 파일로 주어진다. 갈 수록 instance와 column의 수가 증가하여 Big Data를 처리하는 분야로 넓어지고 있다.

만일 데이터를 받게 되면 어떤 것을 먼저 할 것인지 생각해보자. 간단한 통계 값을 적용하는 것을 생각해볼 수 있다. 데이터의 평균, 표준편차, 중간값, 최댓값 등등이 있다. 이를 통해 분포에 대한 감을 잡을 수는 있을 것이다. 만일 위의 그림처럼 두 개의 그룹화 되어있는 데이터를 받았을 때 통계 값들이 의미가 여전히 있는지 질문을 해볼 필요가 있다.

Exploratory Data Analysis는 데이터를 분석하는 방법에 대한 것이다. 데이터를 초기에 조사할 때 사용하는 데이터 분석에 관한 것이며, 분포 통계를 계산하기 위한 패턴을 발견하고, 가설을 검증하는 것을 의미한다. 일반적인 도구로 Clustering과 Dimension reduction 등이 사용된다.

Clustering이란 label이 없이 학습되는 Unsupervised learning에 해당한다. 데이터의 그룹을 찾는 Task가 주를 이룬다. 위의 그림처럼 데이터가 주어지면 그룹을 만드는 것으로 이해하면 된다.

Data point를 주어지고 해당 point를 기준으로 cluster를 생성한다. 동일한 Cluster끼리는 비슷한 성질을 가지고 있으면 vice versa
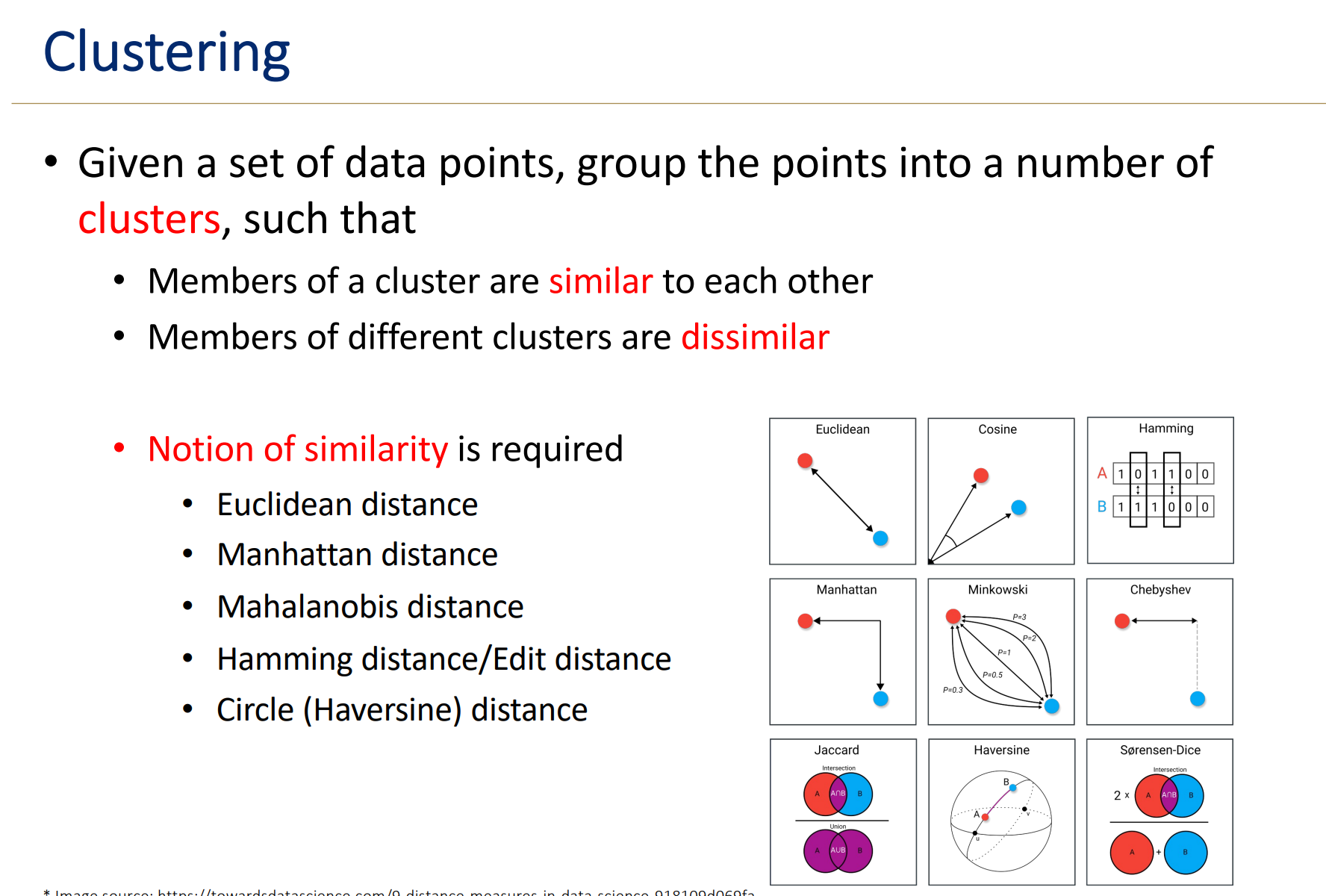
그렇다면 Similarity를 판정하는 기준은 무엇이 있는가. 보통 클러스터 안의 데이터의 Distance를 통해서 그 관계를 파악한다. Distance를 구하는 방법도 여러가지가 있다.

이런 Clustering을 꼭 해야할 필요가 있을까? 고차원 데이터에 대해서 데이터가 갖고 있는 문제가 있기 때문이다.

Clustering의 접근 방식에는 여러 가지가 존재한다. Hierarchical clustering 방법인 Connectivity-based 접근, k-means 알고리즘을 사용하는 Centroid-based 접근이 존재한다. 나머지 두 개도 존재하지만 첫 두가지를 먼저 공부할 것이다.

Hierarchical Clustering이란 계층 구조를 만드는 Clustering에 해당한다. Set of Data point로부터 Tree 모양의 계층 구조 dendrogram을 만든다. 이때는 Distance Matrix를 사용한다.

가장 Base로부터 Distance를 측정하여 더 가까운 Group에 묶는 방식으로 이루어진다.

그렇다면 언제까지 계층구조를 쌓아서 Cluster를 진행할 것인지에 대한 의문이 들것이다. Desired Level에서 dendrogram을 잘라서 Clustering을 얻는 방식을 따른다. 하지만 어느 Depth에서 자르냐에 따라 Cluster가 달라진다는 것이 특징이다.

더 아래서 자르게 되는 경우 cluster의 개수가 3개로 증가하는 것을 볼 수 있다.

그리고 계층을 위에서 아래로 하는 Top-down 방식인지, 아래서 위로 하는 Bottom-up 방식인지에 따라 나뉜다.

Bottom-UP 방식인 Agglomerative Clustering 방식은 초기에 각각의 Data point가 하나의 Cluster가 된다. 반복적으로 가까운 두 개의 Cluster를 하나의 Cluster로 합치게 된다. 여기서 나올 수 있는 질문은, Cluster에 있는 많은 Point 가운데 하나로 표현할 수 있는지, 가까운 클러스터를 결정할 수 있는지, 클러스터를 어떻게 병합하는지에 대한 것이다.

첫 번째 질문인 Cluster의 위치를 어떻게 표현하는지에 대한 것부터 해보자. Centroid의 개념을 적용하여 Cluster 멤버들 간의 평균을 해당 Cluster의 위치로 표현하는 방식을 취한다. Gaussian의 이론이 Intuitive하게 들어가 있는 것을 확인할 수 있다. Skewed 되어 있는 Cluster라면 Average가 아닌 Median을 취하는 방식도 사용되기도 한다.

두 번째로 cluster 간의 가까운 정도를 결정하는 지에 대한 질문이다. 이는 첫 번째 구한 Centroid 간의 거리를 측정하여 추정할 수 있다.

Centroid 방식이 아니라 Cluster 간의 거리가 가장 가까운 지점을 선택하여 거리를 측정하는 방식도 존재한다. 이는 Single Link라고 표현한다.

마찬가지로 먼지점을 선택해서 Nearness를 측정하는 방식이 존재한다. 이렇게 3가지의 방식이 존재하며 각 특징이 있다. Single Link의 경우 Clustering의 결과가 빨리 나오는 경향이 있다. . 반면 Complete link의 경우 좀 더 느리게 연산이 처리된다. 이는 좀더 Compact한 Cluster를 만든다. 이 뜻은 더 멀리있는 Data를 사용하여 Cluster를 만들기 때문에 Diameter가 더 작게 형성될 수 있음을 의미한다.

읽어보면서 정리하자.

여전히 Bottom-up 방식 Clustering 방법에 대해서 다루고 있다. 세번째 질문이다. Cluster를 합치는 것을 언제 멈춰야 하는가. 첫 번째 접근은 k를 미리 선정하여 k개의 Cluster가 구해지면 멈추는 방식이다. 두 번째 접근은 Cohesion이 낮아지게 하는 Cluster를 형성할 때 멈추는 것이다. Elbow Method로 알려져있다.

해당 알고리즘을 살펴보면 각각의 단계에 pairwise하게 거리를 구하고 가장 작은 거리의 Cluster를 Merge하는 방식을 택하고 있다. 하지만 이 방식은 Time Complexity가 너무 오래 걸린다는 문제점이 있다. 여기까지가 Connectivity-based approach에 해당한다.



